We came across an excellent 1992 paper by Gregor Kiczales: Towards a New Model of Abstraction in Software Engineering (pdf). If you are interested in abstractions, interface design, or portability, we consider this classic paper a “must read”. It is one of our favorites and has changed how we approach interfaces and abstraction.
In this paper, Kiczales addresses the common problem with abstraction: even when an abstraction works extremely well for our application, the underlying implementation may not. This is troubling because we are supposed to be able to ignore those implementation details! To address this problem, Kiczales advocates for the idea of “open implementations”. While the paper proposes that this will work through a language feature, the general idea is sufficiently interesting to be worth our consideration.
We have to keep in mind that this was written in 1992, and in some sense we live in a completely different software world. Much of the software we integrate into our products is available directly as source code that we can view and modify to our heart’s content. But this isn’t what the paper means by “open implementations”, and in some sense I don’t think it’s even ideal. Because the open source model primarily gives us a binary decision: use the abstractions as-is, or take complete ownership over the abstraction’s implementation in order to meet your specific needs. That might work, but there has to be a better way, right?
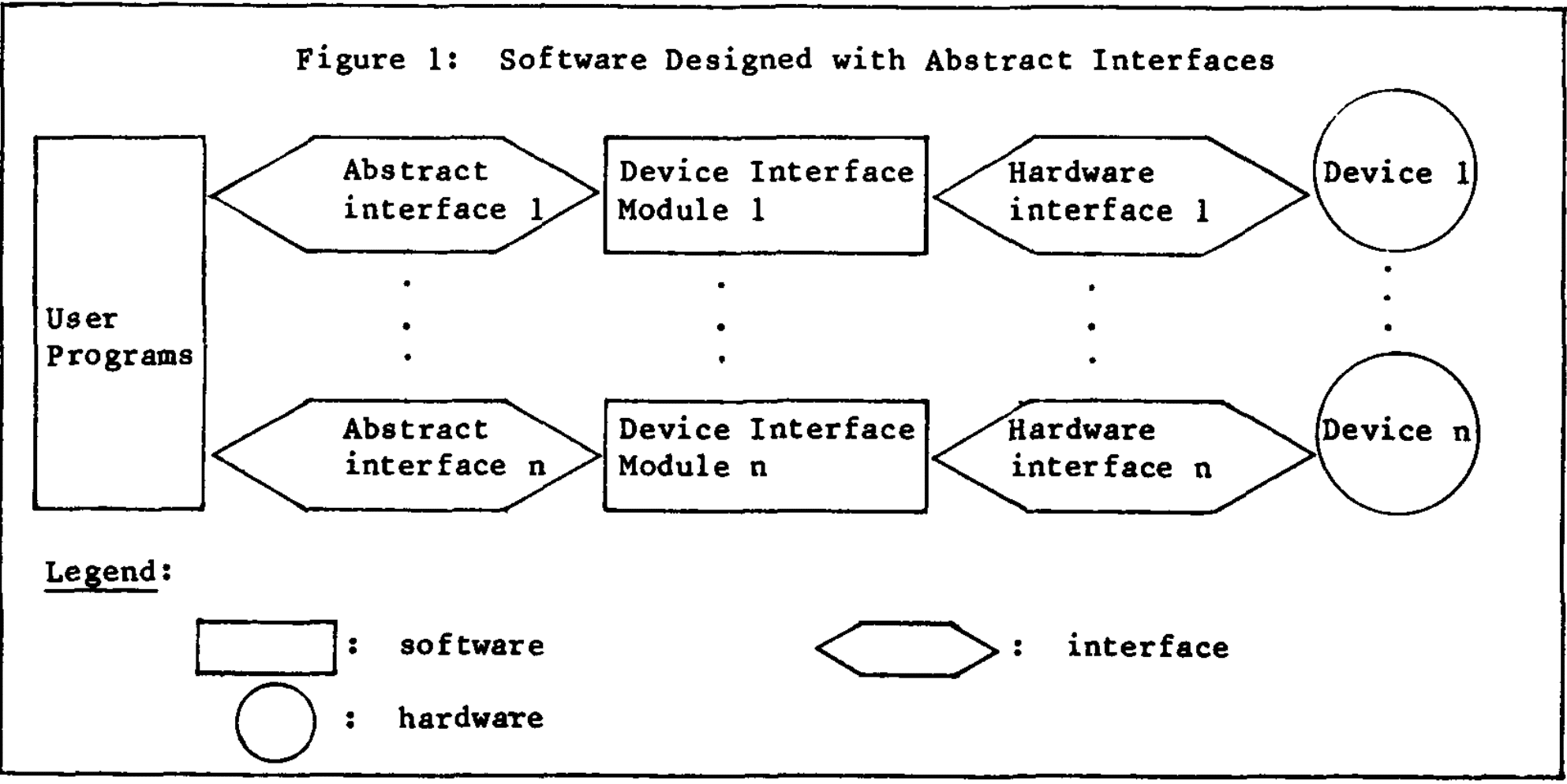
This paper describes the issues with imperfect abstractions and presents a potential solution to the problem by allowing for the customization of the abstraction itself. Kiczales proposes that we think about every module as having two interfaces. There is the good-old-fashioned abstract interface that should ideally be agnostic to the underlying implementation details. The second interface is one that allows users to adjust the module’s implementation according to their needs. This secondary interface grants users the ability to incrementally specify the behaviors they want without having to worry about those implementation details they don’t care about.
Abstract
This is an abridged version of a longer paper in preparation. The eventual goal is to present, to those outside of the reflection and meta-level architectures community, the intuitions surrounding open implementations and the use of meta-level architectures, particularly metaobject protocols, to achieve them.
The view of abstraction on which software engineering is based does not support the reality of practice: it suggests that abstractions hide their implementation, whereas the evidence is that this is not generally possible. This discrepancy between our basic conceptual foundations and practice appears to be at the heart of a number of portability and complexity problems.
Work on metaobject protocols suggests a new view, in which abstractions do expose their implementations, but do so in a way that makes a principled division between the functionality they provide and the underlying implementation. By resolving the discrepancy with practice, this new view appears to lead to simpler programs. It also has the potential to resolve important outstanding problems surround reuse, software building blocks, and high-level program- ming languages.
Files
Reading Club Discussion
This paper was selected for our members’ reading club. Follow this link to discuss the paper.
Key Lessons
This image and its explanatory figure summarizes the key point of the paper:
Kiczales proposes that we think about every module as having two interfaces. There is the good-old-fashioned abstract interface that should ideally be agnostic to the underlying implementation details. The second interface is one that allows users to adjust the module’s implementation according to their needs. This secondary interface grants users the ability to incrementally specify the behaviors they want without having to worry about those implementation details they don’t care about.
Barring a special language feature, what might this implementation interface look like in practice? Based on the current idioms in our own toolkit, we can see a few different ways to enable this secondary implementation interface:
- We can supply multiple implementations for a common interface (such as with embeddedartistry/libmemory), allowing users to choose between implementations at build time (or extend this set with their own)
- We can allow users to supply their own implementations for key process steps if the default implementation isn’t suitable. This can be done using the Strategy pattern, the Template Method pattern, callbacks, weakly linked functions, etc.
- Like Jacob Beningo advocates for in Reusable Firmware Development, we can use a configuration table to allow users to modify and tune implementation details.
- Like the Wayne brothers advocate for in Patterns in the Machine, we can make every fixed parameter in our module configurable via a compiler definition in the event they want to override our defaults.
Further Reading
We think this is a significant idea, and one we are exploring further in the following courses:
- Designing Embedded Software for Change
- View Software Components as Having Two Kinds of Interfaces lesson
- Each of the supporting techniques mentioned above (and more) are explored in depth within this course.
- Abstractions and Interfaces
Bibliography Selections
I always try to find what to read next by searching through the bibliographies of books and papers that interest me. Here are some entries that jump out at me for potential future reads:
- Gregor Kiczales. Metaobject protocols — why we want them and what else they can do. In Andreas Paepcke, editor, Object-Oriented Programming: The CLOS Perspective. MIT Press, 1992.
- John M. Lucassen. Types and effects: Towards the integration of functional and imperative programming. Technical Report MIT/LCS/TR-408, MIT, August 1987.
- Mary Shaw and Wm. A. Wulf. Towards relaxing assumptions in languages and their implementations. In SIGPLAN Notices 15, 3, pages 45–51, 1980.
Highlights and Commentary
We’ve divided the paper into the following general themes:
- The Nature of Abstractions
- The Problems with Abstraction
- Open Implementations
- Problems with Closed Implementations of Abstractions
- Think About Two Interfaces
- Summarizing the Points
- A Segway: Software and Physics
The Nature of Abstractions
From the opening of the paper:
We now come to the decisive step of mathematical abstraction: we forget about what the symbols stand for… [The mathematician] need not be idle; there are many operations he can carry out with these symbols, without ever having to look at the things they stand for.
— Hermann Weyl, “The Mathematical Way ofThinking”
(This appears at the beginning of the Building Abstractions With Data chapter of “Structure and Interpretation of Computer Programs” by Harold Abelson and Gerald Jay Sussman.)
General note:
abstractions do expose their implementations, but do so in a way that makes a principled division between the functionality they provide and the underlying implementation.
Terms we commonly use:
The horizontal lines in the figure are commonly called “abstraction barriers,” “abstractions” or “interfaces.” Each provides useful functionality while hiding “implementation details” from the client above.
To the degree that an abstraction provides powerful, composable functionality, and is free of implementation issues, we call it “clean” or “elegant.”
There seem to be (at least) three basic principles underlying our view of abstraction:
The first, and most important, has to do with management of complexity. In this sense, abstraction is a primary concept in all engineering disciplines and is, in fact, a basic property of how people approach the world. We simply can’t cope with the full complexity of what goes on around us, so we have to find models or approximations that capture the salient features we need to address at a given time, and gloss over issues not of immediate concern.
Second, is a convention that a primary place to draw an abstraction boundary is between those aspects of a system’s behavior that are particular to a particular implementation vs. those aspects of its behavior that common across all implementations.
Third, is a sense that not only is the kind of abstraction boundary that arises from the second principle useful, it is in fact the only one it appropriate to give to clients. That is, we believe that issues of an interface’s implementation are not of concern to, and should be completely hidden from, clients.
Upon these three basic principles lay our goals:
Layered on top of these three principles are our goals of portability, reusability and in fact the whole concept of system software. The idea has been that by taking commonly useful, “basement-level,” functionality —memory allocators, file systems, window systems, databases, programming languages etc. —giving it a general-purpose interface, and isolating the client from the implementation, we could make it possible for a wide range of clients to use the abstraction without caring about the implementation. Portability stems in particular from isolating the client from implementation details; this makes it possible to have other implementations of the abstraction which the client code can be ported to. Reuse stems in particular from making the abstraction general-purpose; the more general it is, the wider a variety of clients that can use it.
The Problems with Abstraction
The “abstract” (the opening paragraphs) points out that we tend to fool ourselves about how abstraction works:
The view of abstraction on which software engineering is based does not support the reality of practice: it suggests that abstractions hide their implementation, whereas the evidence is that this is not generally possible. This discrepancy between our basic conceptual foundations and practice appears to be at the heart of a number of portability and complexity problems.
The paper continues in this vein, following the three principles and the goals built atop them:
As wonderful as this may sound, few experienced programmers would be surprised if this code didn’t quite work. That is, it might work, but its performance might be so bad as to render it, in any practical sense, worthless.
the implementor is faced with a number of tradeoffs, in the face of which they must make decisions. No matter what they do, the window system will end up tuned for some applications and against others.
Implementation decisions based on these assumptions, once made, become locked away behind the abstraction barrier as implementation details.
The above is one reason we make our assumptions explicit in our interface documentation – we don’t want them locked away, requiring users to go hunting!
This goes back to the point made in the note re: “As wonderful as it may sound…”
So, predicting and/or understanding the performance properties of this program can only be done with knowledge of internal aspects of the window system implementation—the so-called “hidden implementation details.”
And we are faced with the facts of reality that most of us have experienced:
But, the reality is that the implementation cannot always be hidden, its performance characteristics can show through in important ways.
Summarizing the point:
What is clear then is that there is a basic discrepancy between our existing view of abstraction and the reality of day-to-day programming. We say that we design clean, powerful abstractions that hide their implementation, and then use those abstractions, without thinking about their implementation, to build higher-level functionality. But, the reality is that the implementation cannot always be hidden, its performance characteristics can show through in important ways. In fact, the client programmer is well aware of them, and is limited by them just as they are by the abstraction itself.
Open Implementations
This is the goal of the new framing of abstractions presented in this paper:
preserve what is good and essential about our existing abstraction framework — essentially the first two bulleted principles—while seeking to address the conflict between the third basic principle and the reality of practice.
I’m definitely already in the boat described below. Open up the implementations! We have no problem here.
very often, as in this example, our abstractions themselves are sufficiently expressive and our implementations may only be deficient in small ways. What we will end up doing is “opening up the implementation,” but doing so in a principled way, so that the client doesn’t have to be confronted with implementation issues all the time, and, moreover, can address some implementation issues without having to address them all.
Problems with Closed Implementations of Abstractions
Cases like the spreadsheet application, where an abstraction itself is adequate for the client’s needs but the implementation shows through and is in some way deficient are common. The machinations the client programmer is forced into by these situations make their code more complex and less portable. These machinations fall into two general categories: (i) Reimplementation of the required functionality, in the application itself, with more appropriate performance tradeoffs; and (ii) coding “between the lines.”
This is why not having open implementation is somewhat problematic:
reimplementing part of the underlying functionality this way increases the size of the application, and, therefore, the total amount of code the programmer must be responsible for.
In addition to making the application strictly larger, reimplementation of underlying functionality can also cause the rest of the application — the code that simply uses the reimplemented functionality — to become more complex. This happens if for some reason the newly implemented functionality cannot be used as elegantly as the original underlying functionality. This in turn can happen if, for any reason, the programmer cannot manage to slide the new implementation in under the old interface.
Simply put, the application programmer doesn’t have the time (even if they do have the interest) to design the new interface as cleanly as might be nice.
Coding between the lines is happens when the application programmer writes their code in a particularly contorted way in order to get better performance.
The example given in the paper for the point above is virtual memory – people work around the virtual memory abstraction and control allocations so they are close together. This is done to control cache behavior and avoid cache misses, which can have a significant performance impact.
Of course, working around abstractions is problematic:
When programmers are forced into these situations, their applications become unduly complex and, more importantly, even less portable.
The original implementation is simple, clear and makes the greatest re-use of the underlying abstractions (i.e. the simple spreadsheet implementation). But, when it comes time to move it to the delivery platform, a number of performance problems come up that must be solved. A wizard is brought in, and through tricks like those mentioned above, manages to improve the performance of the application. Effectively, the wizard convolves the original simple code with their knowledge of inner workings of the delivery platform.The term convolves is chosen to suggest that, as a result of the convolution, properties of the code which had been well localized become duplicated and spread out.) In the process, the code becomes more complex and implicitly conformant to the delivery platform.
When it comes time to move it to another platform, the code is more difficult to work with, and because of the implicit conformance, ti is difficult to tell just why things are the way they are.
When an application is originally written on a fast machine, the code can start out being simple. To port the code to a delivery platform a wizard—someone who understands the inner workings of the delivery platform— is brought in to tune the code. The application gets larger and more complex, and above all it becomes implicitly adapted to the delivery platform. It is then even more difficult to move it to another platform.
- I found a large number of programs perform poorly because of the language’s tendency to hide “what is going on” with the misguided intention of “not bothering the programmer with details.”
– N. Wirth, “On the Design of Programming Languages”
Perhaps this is a summary of the above points: the supposedly hidden properties of the implementation are critically getting in the way. Leaky abstractions, in Joel Spolsky’s terms.
While the CLOS language abstraction itself is perfectly adequate to express the behavior they desire, supposedly hidden properties of the implementation—the instance representation strategy — are critically getting in the way.
Think About Two Interfaces
So what do we do? Think about two interfaces for our abstractions! The approach described in the paper turns now to a language feature, but we think the general idea itself is most important.
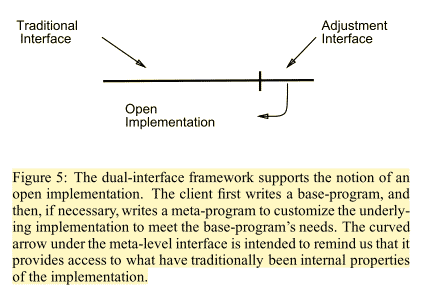
In the metaobject protocol approach, the client ends up writing two programs: a base-language program and an (optional)meta-language program. The base-language program expresses, the desired behavior of the client program, in terms of the functionality provided by the underlying system. The meta-language program can customize particular aspects of the underlying system’s implementation so that it better meets the needs of the base-language program.
Figure 5: The dual-interface framework supports the notion of an open implementation. The client first writes a base-program, and then, if necessary, writes a meta-program to customize the underlying implementation to meet the base-program’s needs. The curved arrow under the meta-level interface is intended to remind us that it provides access to what have traditionally been internal properties of the implementation.
(Figured noted above)
The two interfaces are the base interface, which is what we are used to, and the meta-level interface, which controls and customizes the implementation to suit the needs of the application programmer.
A high-level system(i.e. CLOS) presents two coupled interfaces: base- and meta-level. The base-level interface looks like the traditional interface any such system would present. It provides access to the system’s functionality in away that the application programmer can make productive use of and which does not betray implementation issues. The client programmer can work with it without having to think about the underlying implementation details.
But, for those cases where the underlying implementation is not adequate, the client has amore reasonable recourse. The meta-level interface provides them with the control they need to step in and customize the implementation to better suit their needs. That is, by owning up to the fact that users needs access to implementation issues (i.e. instance implementation strategy), and providing an explicit interface for doing so, the metaobject protocol approach manages to retain what is good about the first two principles of abstraction.
This is important because we are good at designing interfaces that do not betray the implementation. We just don’t have a way to deal with the control of implementation details that then impact the program.
we have become quite good at designing interfaces that do not themselves betray the implementation.
We should be able to make base-level interfaces even more clean because we will now have a principled place to put implementation issues that the client must have access to— the meta-level interface.
What follows are considerations of how a meta-level interface should be approached.
Scope control means that when the programmer uses the metalevel interface to customize the implementation, they should be given appropriate control over the scope of the specialization.
Other classes, particularly classes that are part of other applications, should not be affected.
Conceptual separation means that it should be possible to use the meta-level interface to customize particular aspects of the implementation without having to understand the entire metalevel interface.
The challenge, as discussed in [LKRR92], is to come up with a sufficiently fine-grained model of the implementation.
Incrementality means that the client who decides to customize some aspect of the implementation tradeoffs wants to do just that: customize those properties. They don’t want to have to take total responsibility for the implementation and they don’t want to end up having to write a whole new implementation from scratch. It must be possible for them to say just what it is they want to have be different, and then automatically reuse the rest of the implementation.
Robustness simply means that bugs in a client’s meta-program should have appropriately limited effect on the rest of the system
What is clear is that there is no one right or most elegant metaobject structure, each has relative costs and advantages, and we need to keep experimenting to learn about how to handle locality this way.
How do we come to build a dual-interface abstraction? Iteratively!
It is also possible to make a basic comment about the way the designer of a dual-interface abstraction—or any open implementation — works: iteratively. They start with a traditional abstraction (i.e., a window system or CLOS), and gradually add meta-level interface as it becomes clear what kinds of ways a close implementation can cause problems for users.
Kiczales argues that it is much better to iterate than to try from the start:
Moreover, it isn’t a good idea to try and make the first version of a new kind of system open in this sense. Opening the implementation critically depends on understanding not just one implementation the clients might want, but also the various kinds of variability around that point they might want. In this mode of working, user bug-reports and complaints about previous versions of the system take on an important value. We can look for places where users complained that they wanted to do X, but the implementation didn’t support it; the idea is to add enough control in the meta-level interface to make it possible to customize the implementation enough to make X viable. (In fact, in work on the CLOS Metaobject Protocol, we spent a lot of time thinking about these kinds of bug reports.)
It suggests that anytime we find ourselves saying “well, I’ll implement this feature a particular way because I think most users will do X,” we should immediately think about the other users, the ones whose options we are about to preempt, and how, using a meta-level interface, we might allow them to customize things so they can do other than X.
You might even think of “Future You” as one of those users 🙂
Summarizing the Points
Here is a great restatement of the main point:
In practice, high-level abstractions often cannot hide their implementations — the performance characteristics show through, the user is aware of them, and would be well-served by being able to control them. This happens because making any concrete implementation of a high-level system requires coming to terms with a number of tradeoffs. It simply isn’t possible to provide a single, fixed, closed implementation of such a system that is “good enough” that all prospective users will be happy with it. In other words, the third principle of abstraction presented above appears to be invalid, at least in actual practice.
Under this framework the abstraction presented by a system is divided into two parts: one that provides functionality in a traditional way and another that provides control over the internal implementation strategies supporting that functionality.
A number of programming language projects have discovered that attempting to give their users a black-box abstraction with a single fixed implementation does not work.
In the previously mentioned paper by Shaw &Wulf they make the claim that top-down programming is fundamentally at odds with reusable code libraries and even the notion of system software. Their argument, as I understand it, is that a reusable library essentially blocks, at the abstraction boundary, the downward flow of design decisions, preventing those decisions from leaking into the library’s implementation as we would like.
From the dual interface abstraction point of view, the conflict is not between top-down programming and reusable code; it is between top down programming and closed implementations of reusable code.
The idea is that reusable code should be like a sponge: It provides basic functionality (the base-level interface), basic structure (the default implementation) but also allows the user to “pour in” important customizations from above to “firm it up.”
This view of top-down programming makes it clear that opening an implementation only to the client immediately above is not enough. We need to do better than that; all layers need to be open to all layers above them. So, for example, when an application is written on top of a high-level language, which itself sits on top of a virtual memory system, the application code needs to be able to control not just how the language uses the memory it is allocated, but also how that virtual memory system allocates that memory.
But a clear lesson from the metaobject protocol work is that users can also take productive advantage of being able to customize the semantics (or behavior) of systems they are building on top of.
What it seems we want to be able to do is to allow the user to use natural base-level concepts and natural meta-level concepts— as if they were the x and y axes of a plane — to get at just what it is in the implementation they want to affect. The problem is that the “points” in the plane spanned by these two axes are not necessarily easy to localize in an implementation.
We are, in essence, trying to find a way to provide two effective views of a system through cross-cutting “localities.”
One strategy—the one that has been prevalent in existing meta-level architectures— is to make the problem easier by delaying the implementation of strategy selection until run-time or thereabouts. So, for example, the existing metaobject protocols address only those issues which do not need to be handled in a compile-time fashion. The various systems that address distribution, concurrency and real-time are also addressing problems which are amenable to architectures with runtime dispatch.
All the dual-interface framework does is:
(i) make it more clear that this problem needs to be solved, and
(ii), give one particular organization to the relation between the two different localities.
Of course, looking at the problem this way makes it clear that we may well want more than two, cross-cutting, effective interfaces to a system—the dual interface framework may quickly become the multi-interface framework.
The “abstractions” we manipulate are not, in point of fact, abstract. They are backed by real pieces of code, running on real machines, consuming real energy and taking up real space. To attempt to completely ignore the underlying implementation is like trying to completely ignore the laws of physics; it may be tempting but it won’t get us very far.
A Segway: Software and Physics
Instead, what is possible is to temporarily set aside concern for some (or even all) of the laws of physics. This is what the dual interface model does: In the base-level interface we set physics aside, and focus on what behavior we want to build; in the meta-level interface we respect physics by making sure that the underlying implementation efficiently supports what we are doing. Because the two are separate, we can work with one without the other, in accordance with the primary purpose of abstraction, which is to give us a handle on complexity. But, because the two are coupled, we have an effective handle on the underlying implementation when we need it. I like to call this kind of abstraction, in which we sometimes elide, but never ignore the underlying implementation “physically correct computing.”
Because we are engineers, not mathematicians, we must respect the laws of physics — we cannot hope to completely ignore the underlying implementation.
What will remain, in the long term, is the intuition of physically correct computing and the requirement that we build open implementations.
700-799 Creative Practices/707 Reading/707.11 Readwise/Articles/Towards a New Model of Abstraction in Software Engineering%%
parent:: Reading Club Papers
parent:: Field Atlas Entries