13 July 2022 by Phillip Johnston • Last updated 7 March 2024
The Open-Closed Principle (OCP) is a software design principle that states:
Software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification.
The OCP can be restated in more familiar terms, such as in Patterns in the Machine: A Software Engineering Guide to Embedded Development:
The Open-Closed Principle (OCP) says that you want to design your software so that if you add new features or some new functionality, you only add new code; you do not rewrite existing code. A traditional example of the OCP is to introduce an abstract interface to decouple a “client” from the “server.”
We prefer an even more generalized form of the OCP: design your software components so that you can add new functionality or customize behavior without changing the source code of the component.
The OCP is the “O” in the SOLID acronym.
Table of Contents:
- Evolution of the OCP
- Applying the OCP
- Benefits
- Balancing Points
- Examples
- Related Concepts
- References
Evolution of the OCP
Bertrand Meyer is the originator of the OCP, and he described it as follows:
A module will be said to be open if it is still available for extension. For example, it should be possible to add fields to the data structures it contains, or new elements to the set of functions it performs.
A module will be said to be closed if [it] is available for use by other modules. This assumes that the module has been given a well-defined, stable description (the interface in the sense of information hiding).
A class is closed, since it may be compiled, stored in a library, baselined, and used by client classes. But it is also open, since any new class may use it as parent, adding new features. When a descendant class is defined, there is no need to change the original or to disturb its clients.
What Meyer described is essentially what we would describe as “implementation inheritance”. Nowadays, the idea of implementation inheritance has fallen out of favor. As a result, some people look negatively at the OCP based on this interpretation of it.
Robert Martin took the idea of the OCP and refocused it on abstract interfaces and polymorphism.
In contrast to Meyer’s usage, this definition advocates inheritance from abstract base classes. Interface specifications can be reused through inheritance but implementation need not be. The existing interface is closed to modifications and new implementations must, at a minimum, implement that interface.
[…]
the implementations can be changed and multiple implementations could be created and polymorphically substituted for each other.
This restatement, focused on abstract interfaces that are closed to change, sounds quite like David Parnas’s information hiding principle. Martin himself notes that “on a module level, this idea is best applied in conjunction with information hiding”.
Martin also provided a helpful restatement of what it means to be “open” and “closed”:
Modules that conform to the open-closed principle have two primary attributes.
- They are “Open For Extension”.
This means that the behavior of the module can be extended. That we can make the module behave in new and different ways as the requirements of the application change, or to meet the needs of new applications.
- They are “Closed for Modification”.
The source code of such a module is inviolate. No one is allowed to make source code changes to it.
More recently, we (and others) generalize the idea even further. The authors of Patterns in the Machine: A Software Engineering Guide to Embedded Development provide the following restatement:
Adding new functionality should not be done by editing existing source code. That is the frame of mind you need to approach designing every module with, and you achieve it by putting together a loosely coupled design.
Our own restatement of the OCP advises us to design your software components so that you can add new functionality or customize behavior without changing the source code of the component..
These two contemporary restatements of the OCP get to the heart of the matter: prevent changes from cascading throughout a system by a) putting up firewalls, b) making components “closed” to specific changes, and c) providing mechanisms to externally extend and control behaviors without modifying a component’s source code.
Applying the OCP
The OCP advises us that software components should be open for extension yet closed for modification. On the surface, this appears to be a conundrum: the typical way one would extend the behavior of a component is by changing it! If a component cannot be changed, how can it be extended?
This question can be attacked from multiple angles:
- Abstract Interfaces
- Providing Hooks for External Customization
- Implementation Decisions
Ensuring a component adheres to the OCP is an explicit design decision. Designers must choose what types of extensions and changes that a component is closed against (or whether the OCP applies to a component at all). Mechanisms must be provided by the component to support the target extensions. To provide actual benefit, the existence of these extension mechanisms is not enough – they must be documented so they can be used effectively to achieve the goals of the OCP. It is also wise to document what changes a component is/isn’t closed against for future maintainers.
Abstract Interfaces
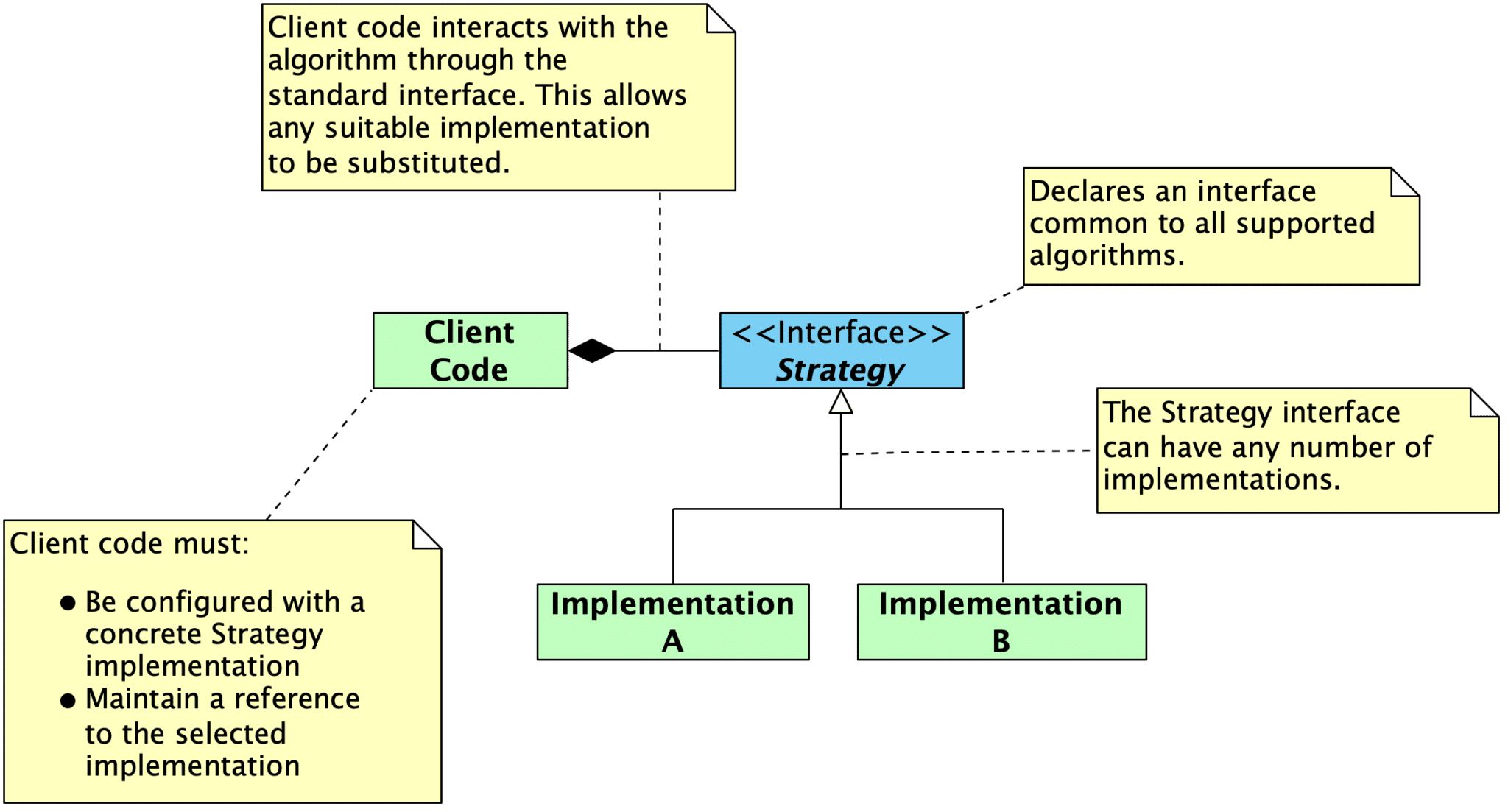
The classical answer to resolving these two competing goals is abstraction. In general, this is a broad answer, since abstraction takes many forms. Martin’s OCP largely focuses on abstract interfaces combined with dynamic polymorphism (i.e., inheritance) or static polymorphism (e.g., templated parameters in C++ that expect a particular interface).
In C++, using the principles of object oriented design, it is possible to create abstractions that are fixed and yet represent an unbounded group of possible behaviors. The abstractions are abstract base classes, and the unbounded group of possible behaviors is represented by all the possible derivative classes. It is possible for a module to manipulate an abstraction. Such a module can be closed for modification since it depends upon an abstraction that is fixed. Yet the behavior of that module can be extended by creating new derivatives of the abstraction.
Abstract interfaces can be viewed as “specifications”, and these specifications can be reused through inheritance even though the implementation is not. The interface specifications will be closed to modifications. New implementations that satisfy the interface can be created, leaving the implementation of the interface open to extension. New behaviors and requirements are implemented by providing new implementations rather than by modifying existing implementations, since those are closed to modifications. In this sense, the OCP can be viewed simply as a restatement of the information hiding principle, and all of the associated advice will apply equally well here.
Providing Hooks for External Customization
Abstract interfaces are a useful tool for achieving the goals of the OCP, but they are not the only tool. Here are techniques that enable your software components to be configured and extended by user applications:
- Configuration Parameters
- Template Method Pattern
- Callbacks
- Communicating Through Queues
- Table-Driven Behavioral Specifications
Configuration Parameters
One of the easiest ways to achieve the OCP is to provide configuration options for your software component. This way, user applications can control the behavior of your component without changing the component’s source code. You can supply configuration options in several ways:
-
Run-time configuration options, such as specifying desired values in a struct that is passed into a component through a constructor or initialization routine
-
C++ template parameters for classes and function
-
Using the preprocessor and #ifndef to provide compile-time configuration using a build system, a dedicated configuration system like KConfig, or a configuration header.
#ifndef SCREEN_WIDTH_PX
#error You must provide a definition for SCREEN_WIDTH_PX.
#endif
#ifndef SCREEN_HEIGHT_PX
#error You must provide a definition for SCREEN_HEIGHT_PX.
#endif
#ifndef PIXELS_PER_BYTE
#define PIXELS_PER_BYTE 8
#endif
#ifndef SCREEN_BUFFER_SIZE_BYTES
// Calculated: (width in px * height in px) / pixels per byte
#define SCREEN_BUFFER_SIZE_BYTES ((SCREEN_WIDTH_PX * SCREEN_HEIGHT_PX) / PIXELS_PER_BYTE)
#endif
The more parameters that can be controlled from outside of your software component, the better. This reduces the likelihood that you will need to change the component in the future.
For more information, see:
Template Method Pattern
The Template Method pattern can provide users with the ability to customize actions taken by your component. You can designate template methods that comprise one or more optional or required steps. These steps can be supplied or overridden by user programs, enabling user applications to change aspects of your component’s behavior without modifying the component source code.
Template methods are useful in the following scenarios:
- Decoupling a component from platform-specific details. The application can specify those based on its target platform. This enables the component to work with any platform that can implement the required step(s).
- Decoupling one component from another. Instead, a template method can be supplied, allowing an external component to connect the components together.
- Allowing users to configure, extend, or override a componet’s behavior to meet their application’s requirements.
For more information, see:
Callbacks
Similar to the Template Method pattern, callback functions provide user applications with customization points that can extend a component’s behavior without modifying its source code. Callback functions are typically invoked when a particular action occurs (e.g., transfer complete callback, error callback). User applications can implement callback handlers in order to connect components together from the outside or to take an application-specific action in response to the event.
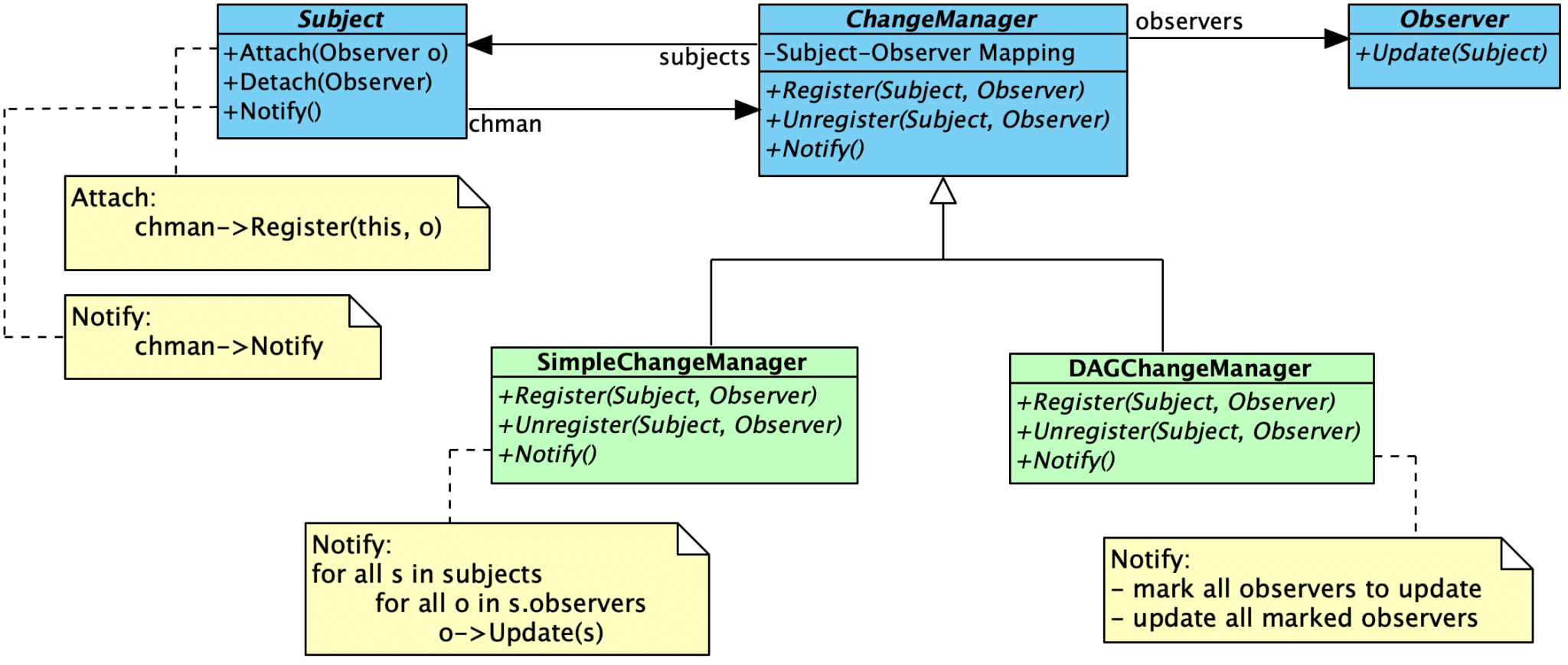
The Observer Pattern can be used in the same way as a callback function. This pattern is useful when there are multiple subscribers who may be interested in an event.
For more information, see:
Communicating Through Queues
Rather than communicating through interfaces, components can instead communicate through queues. The data format (closed to modification) passed through the queue becomes the primary interface. Producers and consumers of information can be swapped out without the need to modify the component(s) on the other end.
Communication through queues can also be combined with other mechanisms, such as template methods or callbacks. This combination can prevent your component from becoming coupled to a specific queue implementation. It also gives your users the flexibility to decide whether or not a queue should be used at all.
For more information, see:
Table-Driven Behavioral Specifications
Some aspects of a component that are likely to change over time can be defined in a table, and the application will be made responsible for supplying the table implementation. The component itself can then become agnostic to the contents, simply understanding how to generically access the information present in the table for its purposes. Changes can be handled through the application’s definition of the table, leaving the source code of component itself unchanged. Tables are also useful for specifying application-specific configuration details.
For more information, see:
Encapsulation
The OCP also depends on proper encapsulation. Within the OCP context, you should be particularly concerned about properly encapsulating implementation details so that they cannot be accessed or modified directly – components should only interact through the published interfaces. This means applying the following two design policies in your system:
- Eliminate Global Variables
- Make Member Variables Private
Eliminate Global Variables
Martin states this more strongly: “No global variables – ever”. He points out that the use of global variables makes the OCP impossible to achieve:
The argument against global variables is like the argument against public member variables. No module that depends upon a global variable can be closed against any other module that might write to that variable. Any module that uses the variable in a way that the other modules don’t expect will break those other modules. It is too risky to have many modules be subject to the whim of one badly behaved one.
For more information, see:
Make Member Variables Private
Similar to the advice to eliminate global variables, all class member variables and “file global” member variables in a component should be made private so they cannot be accessed from outside of the component.
In OOD, we expect that the methods of a class are not closed to changes in the member variables of that class. However we do expect that any other class, including sub- classes are closed against changes to those variables. We have a name for this expectation, we call it: encapsulation.
– Robert Martin
Benefits
The OCP is an essential tool in designing software for change. Intentionally designing your software components to be easily extended and closed to change improves the ability of your systems to respond to change.
In the strictest sense, you are designing components that a) never change and b) are implemented against an abstract interface. Changes in requirements will then mean that you are going to a) create a new extension to existing behavior, or b) create a new component to implement the new requirements for the existing interface(s). In either case, you will not change old code to get your desired behavior.
Components that adhere to the OCP act as a “firewall” against change. Because you are adding new code instead of modifying existing code (and working through abstract interfaces), changes are prevented from cascading throughout a system. They are isolated to the creation of a new component and its integration into the system.
All systems change during their life cycles. This must be borne in mind when developing systems expected to last longer than the first version.
– Ivar Jacobson
Balancing Points
The OCP is best viewed as a goal or a guiding light. Software components cannot be 100% closed against all extensions or changes. Some changes will affect “closed” components by their nature. For example:
- The methods of a class or component are not closed to changes in the private variables of that component, but external components interfacing with that component are closed to changes in the private variables.
- Components are not closed to interface changes. They will cascade into all components that use the interface.
- Components are not closed to changes resulting from discovering an implementation error, design error, or error in understanding.
Examples
The following examples show how different techniques can be used (and combined) to achieve the OCP in production code.
- The AX5043 driver uses a template method to allow applications to configure the driver’s SPI interactions without modifying the driver source code. Several configuration parameters are also provided through “instance structures”, allowing applications to configure the radio for the intended use case. Multiple radio instances can be supported with the use of multiple instance structures.
- embeddedartistry/libc provides common implementations for standard library functions and headers, while deferring architecture-specific implementation details to architecture-specific headers. New processor architectures can be supported by creating a new architecture-specific tree, defining the types appropriately for that platform, and supplying additional function implementations as needed. The base headers and function implementations require no modifications.
- embeddedartistry/libmemory provides a single, common memory allocation interface (i.e.,
malloc and friends) with multiple implementations to the interface that can be selected by users. New allocation schemes are added by creating new implementations. This library also uses the template method pattern to enable user applications to externally specify locking behavior for thread safety without modifying the implementation source.
- The embeddedartistry/printf library provides a template method that applications can use to configure the output for the
printf family of functions (putchar_()), as well as multiple compile-time configuration options that can tune the library for a specific application and platform.
- The Embedded Virtual Machine framework heavily uses the OCP by applying many of the techniques discussed above: abstract interfaces with multiple implementations, template methods, configuration options, and callbacks.
- The Patterns in the Machine repository was designed with the OCP in mind. Using the OCP is also discussed in the corresponding book.
- The OCP is the “O” in the SOLID acronym
- Information Hiding is closely related to the OCP. As Robert Martin pointed out, the two concepts are best employed together.
[…] on a module level, this idea is best applied in conjunction with information hiding.
- Encapsulation, especially of private data, is a necessity when designing around the OCP.
- Abstract Interfaces are commonly used to achieve the OCP.
- Several design patterns can be used to achieve the OCP:
References
-
Information Hiding
-
Wikipedia: Open-Closed Principle
-
Wikipedia: SOLID
The open–closed principle: “Software entities … should be open for extension, but closed for modification.”
-
Object Oriented Software Construction by Bertrand Meyer
A class is closed, since it may be compiled, stored in a library, baselined, and used by client classes. But it is also open, since any new class may use it as parent, adding new features. When a descendant class is defined, there is no need to change the original or to disturb its clients.
-
Design Principles and Design Patterns by Robert Martin
A module should be open for extension but closed for modification.
Of all the principles of object oriented design, this is the most important. It originated from the work of Bertrand Meyer It means simply this: We should write our modules so that they can be extended, without requiring them to be modified. In other words, we want to be able to change what the modules do, without changing the source code of the modules.
This may sound contradictory, but there are several techniques for achieving the OCP on a large scale. All of these techniques are based upon abstraction. Abstraction is the key to the OCP. Several of these techniques are described below.
The techniques Martin mentions to achieve the OCP are dynamic polymorphism (i.e., inheritance from an abstract interface) and static polymorphism (i.e., polymorphism acheived through templates and generics).
Architectural Goals of the OCP. By using these techniques to conform to the OCP, we can create modules that are extensible, without being changed. This means that, with a little forethought, we can add new features to existing code, without changing the existing code and by only adding new code. This is an ideal that can be difficult to achieve, but you will see it achieved, several times, in the case studies later on in this book.
Even if the OCP cannot be fully achieved, even partial OCP compliance can make dramatic improvements in the structure of an application. It is always better if changes do not propogate into existing code that already works. If you don’t have to change working code, you aren’t likely to break it.
-
“The Open-Closed Principle” by Robert Martin
As Ivar Jacobson said: “All systems change during their life cycles. This must be borne in mind when developing systems expected to last longer than the first version.” How can we create designs that are stable in the face of change and that will last longer than the first version? Bertrand Meyer gave us guidance as long ago as 1988 when he coined the now famous open-closed principle. To paraphrase him:
SOFTWARE ENTITIES (CLASSES, MODULES, FUNCTIONS, ETC.) SHOULD BE OPEN FOR EXTENSION, BUT CLOSED FOR MODIFICATION.
When a single change to a program results in a cascade of changes to dependent modules, that program exhibits the undesirable attributes that we have come to associate with “bad” design. The program becomes fragile, rigid, unpredictable and unreusable. The open- closed principle attacks this in a very straightforward way. It says that you should design modules that never change. When requirements change, you extend the behavior of such modules by adding new code, not by changing old code that already works.
Modules that conform to the open-closed principle have two primary attributes.
- They are “Open For Extension”.
This means that the behavior of the module can be extended. That we can make the module behave in new and different ways as the requirements of the application change, or to meet the needs of new applications.
- They are “Closed for Modification”.
The source code of such a module is inviolate. No one is allowed to make source code changes to it.
It would seem that these two attributes are at odds with each other. The normal way to extend the behavior of a module is to make changes to that module. A module that cannot be changed is normally thought to have a fixed behavior. How can these two opposing attributes be resolved?
Abstraction is the Key.
In C++, using the principles of object oriented design, it is possible to create abstractions that are fixed and yet represent an unbounded group of possible behaviors. The abstractions are abstract base classes, and the unbounded group of possible behaviors is represented by all the possible derivative classes. It is possible for a module to manipulate an abstraction. Such a module can be closed for modification since it depends upon an abstraction that is fixed. Yet the behavior of that module can be extended by creating new derivatives of the abstraction.
Since programs that conform to the open-closed principle are changed by adding new code, rather than by changing existing code, they do not experience the cascade of changes exhibited by non-conforming programs.
It should be clear that no significant program can be 100% closed. […] In general, no matter how “closed” a module is, there will always be some kind of change against which it is not closed.
Since closure cannot be complete, it must be strategic. That is, the designer must choose the kinds of changes against which to close his design. This takes a certain amount of prescience derived from experience. The experienced designer knows the users and the industry well enough to judge the probability of different kinds of changes. He then makes sure that the open-closed principle is invoked for the most probable changes.
In OOD, we expect that the methods of a class are not closed to changes in the member variables of that class. However we do expect that any other class, including sub- classes are closed against changes to those variables. We have a name for this expectation, we call it: encapsulation.
Make all Member Variables Private.
No Global Variables — Ever.
The argument against global variables is similar to the argument against pubic member variables. No module that depends upon a global variable can be closed against any other module that might write to that variable. Any module that uses the variable in a way that the other modules don’t expect, will break those other modules. It is too risky to have many modules be subject to the whim of one badly behaved one.
On the other hand, in cases where a global variable has very few dependents, or cannot be used in an inconsistent way, they do little harm. The designer must assess how much closure is sacrificed to a global and determine if the convenience offered by the global is worth the cost.
Again, there are issues of style that come into play. The alternatives to using globals are usually very inexpensive. In those cases it is bad style to use a technique that risks even a tiny amount of closure over one that does not carry such a risk. However, there are cases where the convenience of a global is significant. The global variables cout and cin are common examples. In such cases, if the open-closed principle is not violated, then the convenience may be worth the style violation.
Conformance to this principle is what yeilds the greatest benefits claimed for object oriented technology; i.e. reusability and maintainability. Yet conformance to this principle is not achieved simply by using an object oriented programming language. Rather, it requires a dedication on the part of the designer to apply abstraction to those parts of the program that the designer feels are going to be subject to change.
-
Patterns in the Machine : A Software Engineering Guide to Embedded Development by John Taylor and Wayne Taylor
The Open-Closed Principle (OCP) says that you want to design your software so that if you add new features or some new functionality, you only add new code; you do not rewrite existing code. A traditional example of the OCP is to introduce an abstract interface to decouple a “client” from the “server.”
…
Restatement:
Adding new functionality should not be done by editing existing source code. That is the frame of mind you need to approach designing every module with, and you achieve it by putting together a loosely coupled design.
PIM’s interpretation of the OCP, then, is quite literally: Adding new functionality should not be done by editing existing source code. That is the frame of mind you need to approach designing every module with, and you achieve it by putting together a loosely coupled design.
Strategic (OCP)—Think long term when designing and implementing modules.
It is also important to recognize that a module cannot be 100% closed against all possible extensions. Furthermore, not every module needs to be OCP friendly. It is the responsibility of the designer, architect, and developer to choose what type of extensions a module is closed against. As with most things in life, good choices come with experience, and a lot of experience comes from bad choices.
-
The Open-Closed Principle. and what hides behind it | HackerNoon.com by Vadim Samokhin